简介
- 免费且开源的实时计算系统
- 简单可靠的处理流式数据,而Hadoop是使用的批处理
- 不受开发语言的限制(kryo序列化库)
hadoop/spark/storm等对比
| * |
hadoop M/R |
spark |
storm |
| 存储 |
磁盘 |
内存 |
内存 |
| 数据集 |
现有数据集 |
现有数据集 |
实时 |
| 任务状态 |
作业管理 |
作业管理 |
常住内存 |
| 常用场景 |
离线的复杂的大数据处理 |
离线的快速大数据处理 |
在线的实时的大数据处理 |
Spark Streaming和Storm类似
read more
storm核心概念
官方抽象图


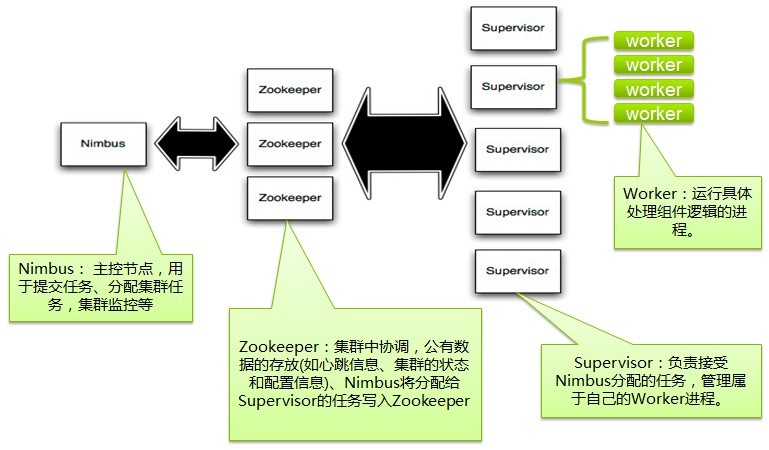
集群结构图
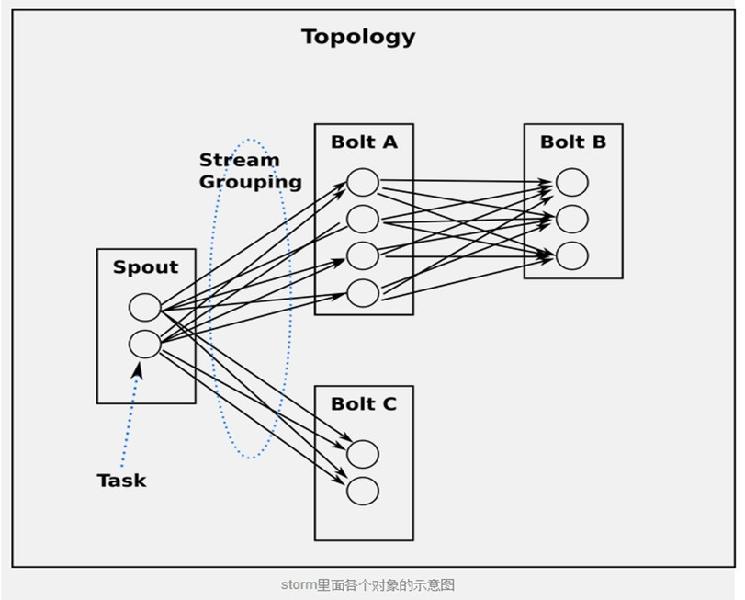
Topologies
一个完整的计算主体,相当于是一个M/R任务,区别是M/R任务执行完会退出,而topology永远运行(除非被主动kill)
Streams、tuples
Storm里面最核心的抽象,Streams使用tuple,tuples可以理解为最小的数据类型元组,可以为 integers, longs, shorts, bytes, strings, doubles, floats, booleans, and byte arrays。也支持自定义可序列化的类型
Spout
数据源,一般是消息队列,将数据发送到Bolts
Bolts
具体执行数据分析的节点
Stream groupings
定义了每个bolt的数据发送策略
- shuffle grouping
- fields grouping
- All grouping(广播,所有bolts都会收到)
- etc.
read more1 read more2
数据的一致性,可靠性
- 每个tuple拥有一个messageId
- Acker机制,每个Topology拥有一个Acker,可以追踪messageId
- Spout、Bolt发出数据后通知Acker自己处理的messageId
- 消息处理失败后,Tuple会被重新发出
举个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
public class WordCountTopology {
public static class SplitSentence extends ShellBolt implements IRichBolt {
public SplitSentence() {
super("python", "splitsentence.py");
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
public static class WordCount extends BaseBasicBolt {
Map<String, Integer> counts = new HashMap<String, Integer>();
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
Integer count = counts.get(word);
if (count == null)
count = 0;
count++;
counts.put(word, count);
collector.emit(new Values(word, count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));
Config conf = new Config();
conf.setDebug(true);
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
}
else {
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
}
|